glTF in Unity optimization - 3. Parallel Jobs
This is part 3 of a mini-series.
Goal
In this episode I wanted to investigate, if the task of converting index/vertex data from binary buffers into Unity structures could be sped up by using parallel jobs.
The abstract steps of converting data in glTFast look like this
- Prepare Jobs
- Allocate memory for the destination Unity data structures
- Schedule Jobs
- Execute Jobs
- Create Meshes from retrieved data structures
- Instantiate GameObjects
The job execution is already threaded via the C# Job system, but one glTF Accessor is always retrieved in one thread and not split up further. For smaller meshes this is probably fine, but I can imagine large meshes may benefit if the work is spread across CPU cores more evenly.
Analysis
Lets do some profiling to get a measure of the status quo. I used a 4 million triangle mesh with indices, positions and texture coordinates only.
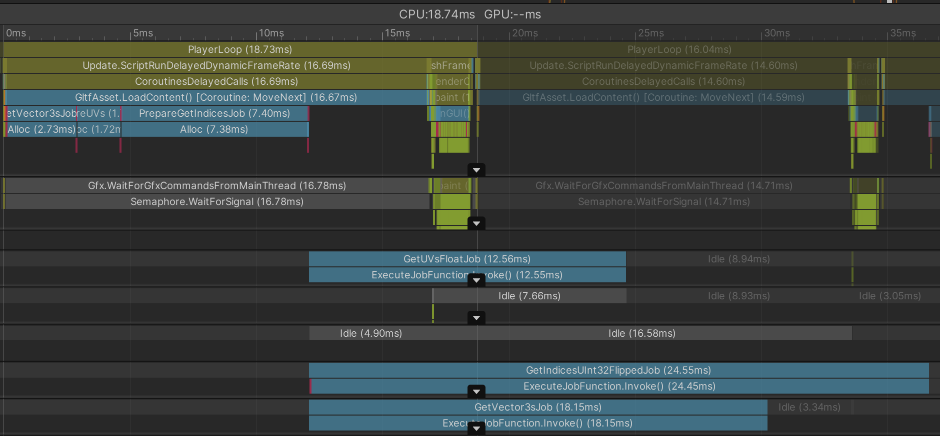
The interesting bit is in the lower half. After scheduling the jobs, the worker threads start the execution roughly at the same time. 3 Workers have nothing to do, the UV job is done after 12.56 ms while the indices job takes the longest ( 24.55 ms ). Since we can only continue to build the mesh after all jobs are finished, 24.55 ms is the starting measure.
What I try to achieve is to spread the work more evenly across the worker threads, so the total computation is finished earlier. If I add up the Job's execution times and divide it evenly by the number of workers (6), I get 9.21 ms, which would be the absolute optimum if there was no overhead for spreading the work. Let's see how close we can get.
Status Quo: Job implementation
There are over 30 different C# Jobs in glTFast, all of which implement the IJob interface and most of the have a main for-loop at their heart.
To make them parallel, they have to implement the IJobParallelFor interface. Let me demonstrate this on one simplified example. This Job retrieves the mesh indices in one loop:
public unsafe struct GetIndicesUInt32Job : IJob {
public int count;
public System.UInt32* input;
public int* result;
public void Execute()
{
int triCount = count/3;
// This is the main loop we want to spread
for (var i = 0; i < triCount; i++) {
result[i*3] = (int)input[i*3];
result[i*3+2] = (int)input[i*3+1];
result[i*3+1] = (int)input[i*3+2];
}
}
}Let's go parallel
Instead of this, we want the Job Scheduler to split this up onto the threads.
public unsafe struct GetIndicesUInt32Job : IJobParallelFor {
public System.UInt32* input;
public int* result;
public void Execute(int index)
{
result[index] = (int)input[index];
}
}Scheduling this job changes a bit:
// old way for IJob
var jobHandle = job.Schedule();
// new way for IJobParallelFor
var jobHandle = job.Schedule(indexCount,1);We now have to provide the number of iterations (index count in the example) to the Schedule method. Before it was a member of the Job struct (public int count;);
The second parameter is called batch count. We get to that soon and leave it at a default 1
First test
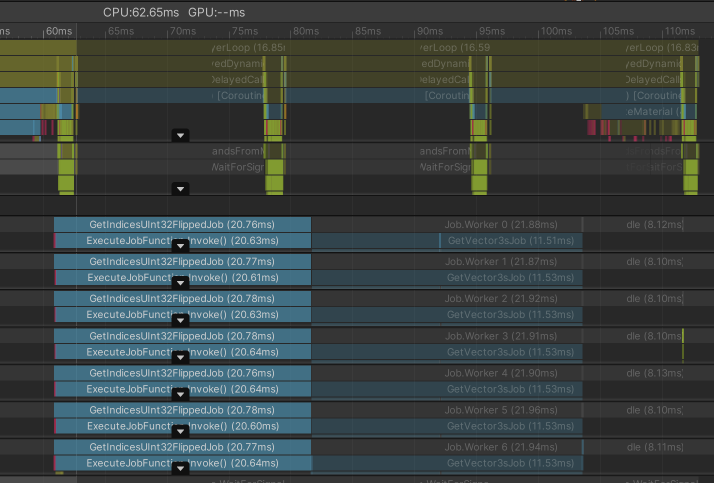
Now the work is spread across workers evenly, but the total execution time went up to over 32 ms! 😱
Reading the documentation explains why. Our new job has little computational complexity but is repeated millions of times. Spreading this iterations across threads does have an overhead and if this is done on a very small/granular level, the overhead is bigger than the gain.
Batch count counts
This is where the batch count parameter comes in. It tells the Job System to not make batches with less iterations than this number. So next thing I did was increase the batch count in test iterations and tried to find a sweet spot. I settled for 50000 for this Job, but results may vary on different (more complex) jobs or different hardware.
Let's see how it performs now:
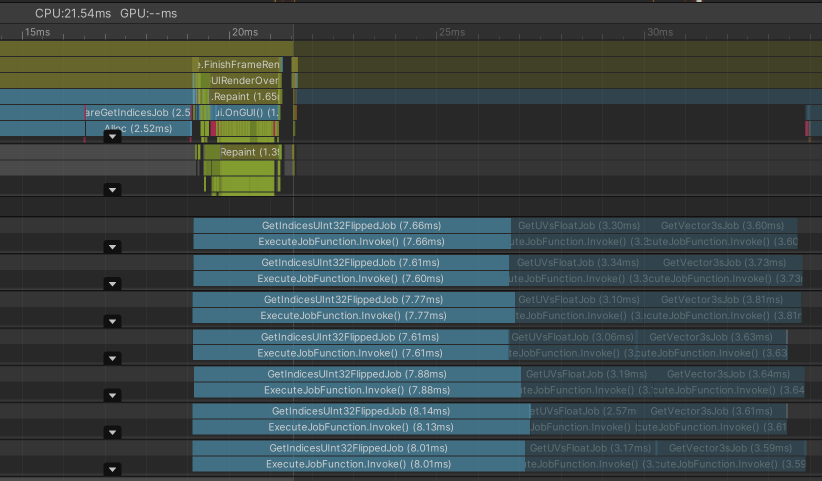
Down to 14.6 ms. That's not as low as the targeted 9.21 ms, but 40% less than the original 24.55 ms. And look how neatly aligned the blue bars on the worker threads are 😍. Good job 😎!
I think the result may be improved further if the batch count is tweaked more carefully on the actual target hardware (which will be mainly mobile in my case). That I still have to do.
Hot loops
Some jobs had an option for normalization, like this one:
public void Execute()
{
if(normalize) {
for (var i = 0; i < count; i++)
{
result[i].x = input[i*2] / 255f;
result[i].y = 1 - input[i*2+1] / 255f;
}
} else {
for (var i = 0; i < count; i++)
{
result[i].x = input[i*2];
result[i].y = 1 - input[i*2+1];
}
}
}There were two design decisions I made when writing this:
- One Job for both normalized and not normalized variants for more convenient Job usage.
- The
normalizecondition is outside of the hot loop. It's a bit more redundant because of this, but it's faster.
When making them parallel, I have to either make two Job types or move the if condition into the loop. I chose the first option for performance reasons:
// "regular" variant:
public unsafe struct GetUVsUInt8Job : IJobParallelFor {
public byte* input;
public Vector2* result;
public void Execute(int i)
{
result[i].x = input[i*2];
result[i].y = 1 - input[i*2+1];
}
}
// And the second, normalized variant:
public unsafe struct GetUVsUInt8NormalizedJob : IJobParallelFor {
public byte* input;
public Vector2* result;
public void Execute(int i)
{
result[i].x = input[i*2] / 255f;
result[i].y = 1 - input[i*2+1] / 255f;
}
}I applied this everywhere and ended up with 43 parallel jobs now (See the commit for details). This was released in glTFast 0.11.0.
Putting it in perspective
Shaving off a couple of milliseconds sure feels nice, but looking at the overall loading time (which is still hundreds of milliseconds), frankly it doesn't really matter that much 🙁
The demo scene profiled here also is an extreme case. Yes, high triangle counts will benefit more, but I guess most content out there is not.
Originally I wanted to go on and see how much Unity.Mathematics and the Burst compiler can speed up the Jobs, but it seems that the energy is spent wiser elsewhere first and get back to that later.
Next up
I'll probably tackle the new Mesh API in an attempt to get these crazy mesh instantiation times down. Stay tuned!
Follow me on Mastodon or Bluesky or subscribe the feed to not miss updates.
If you liked this read, feel free to
